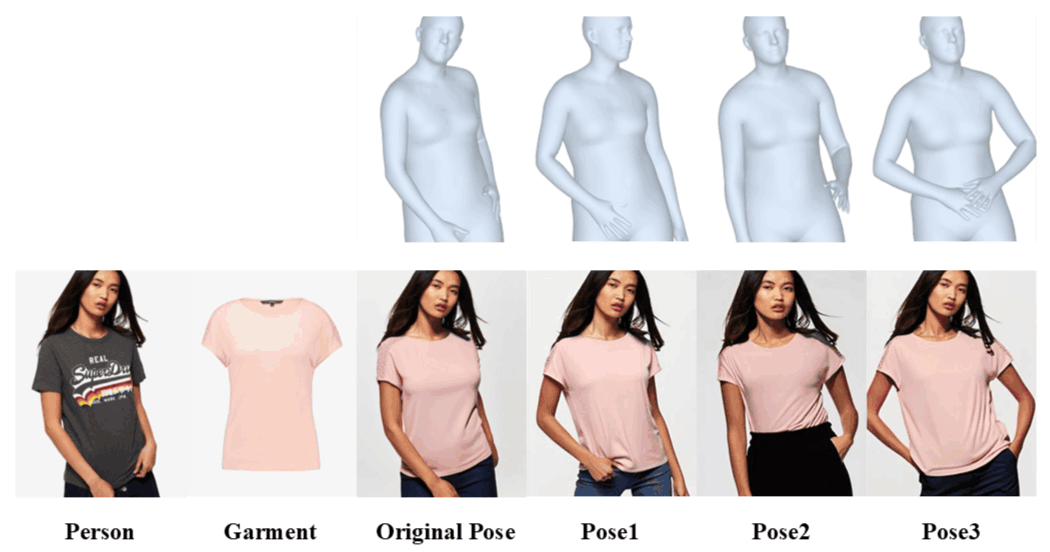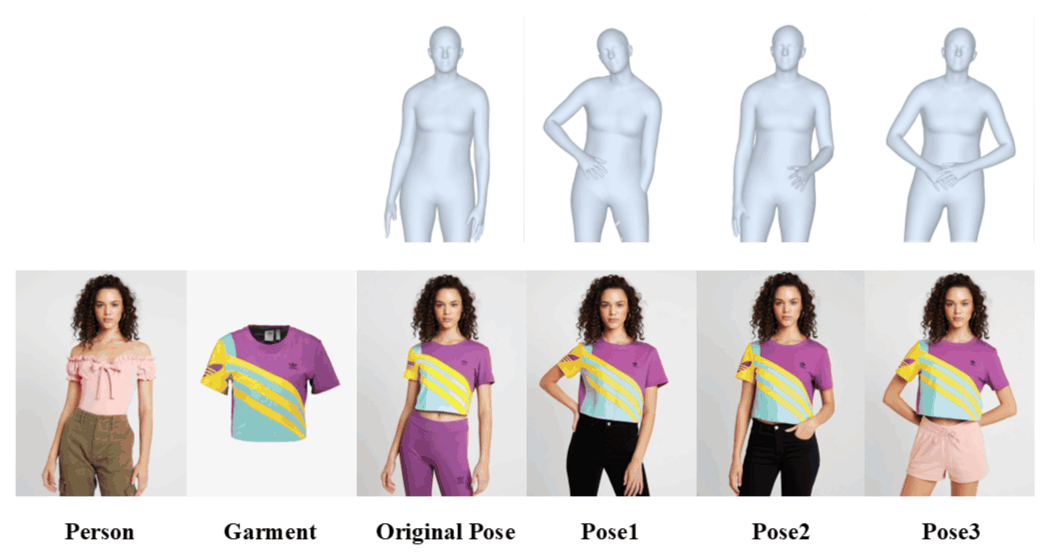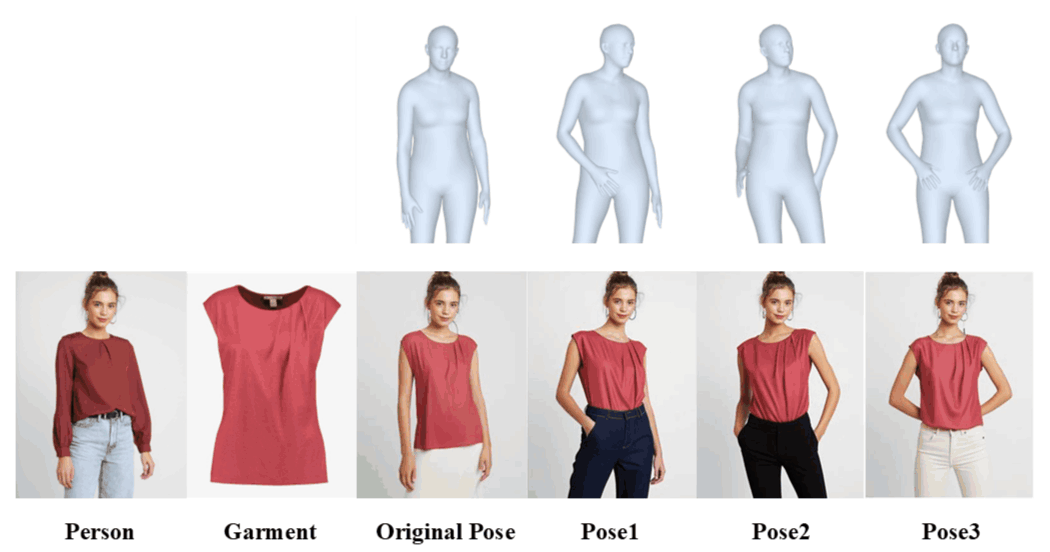
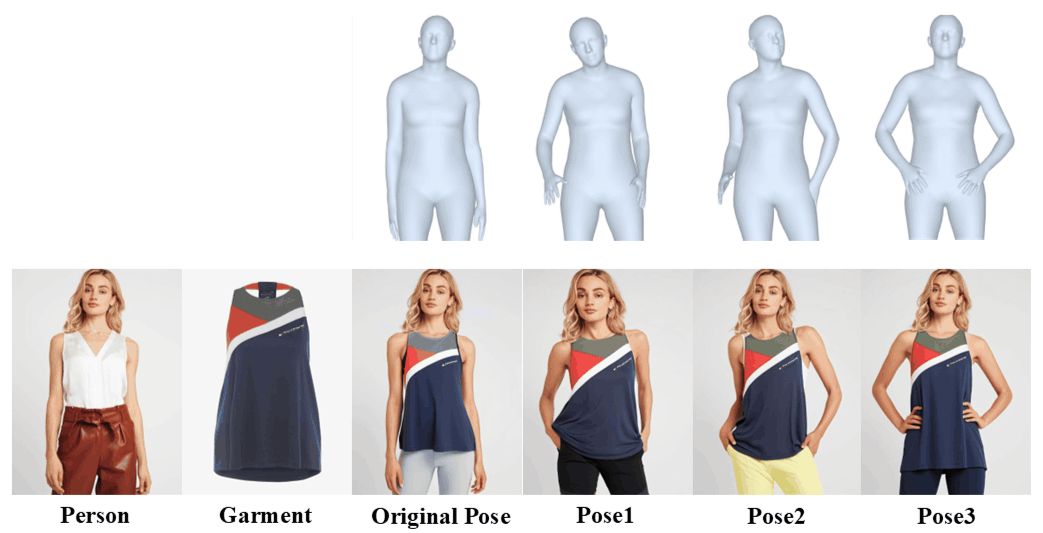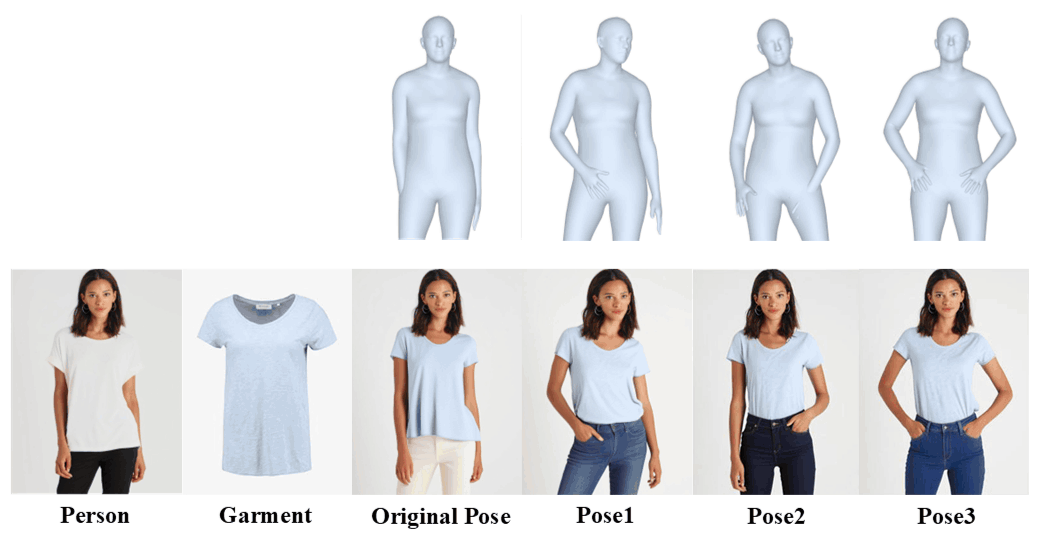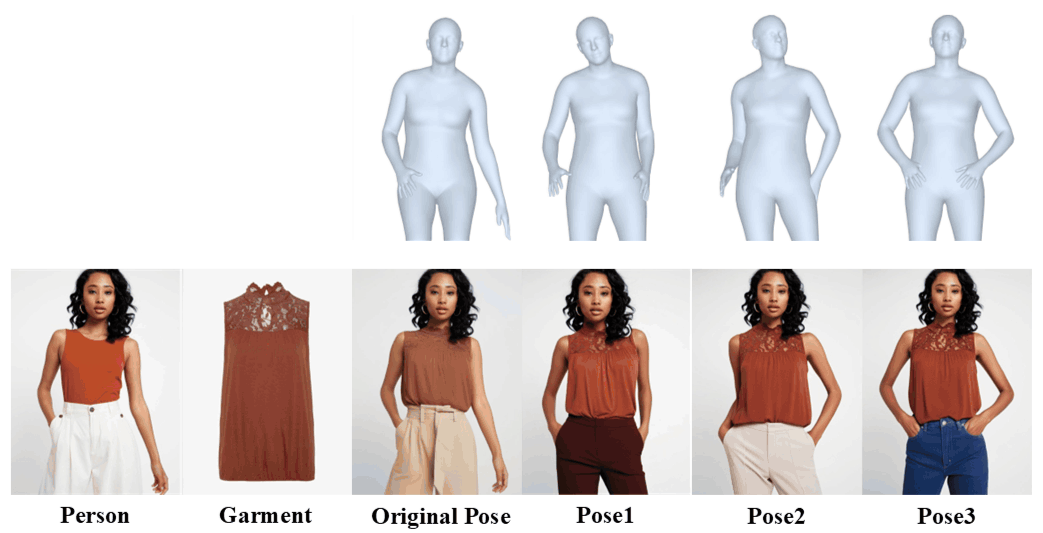
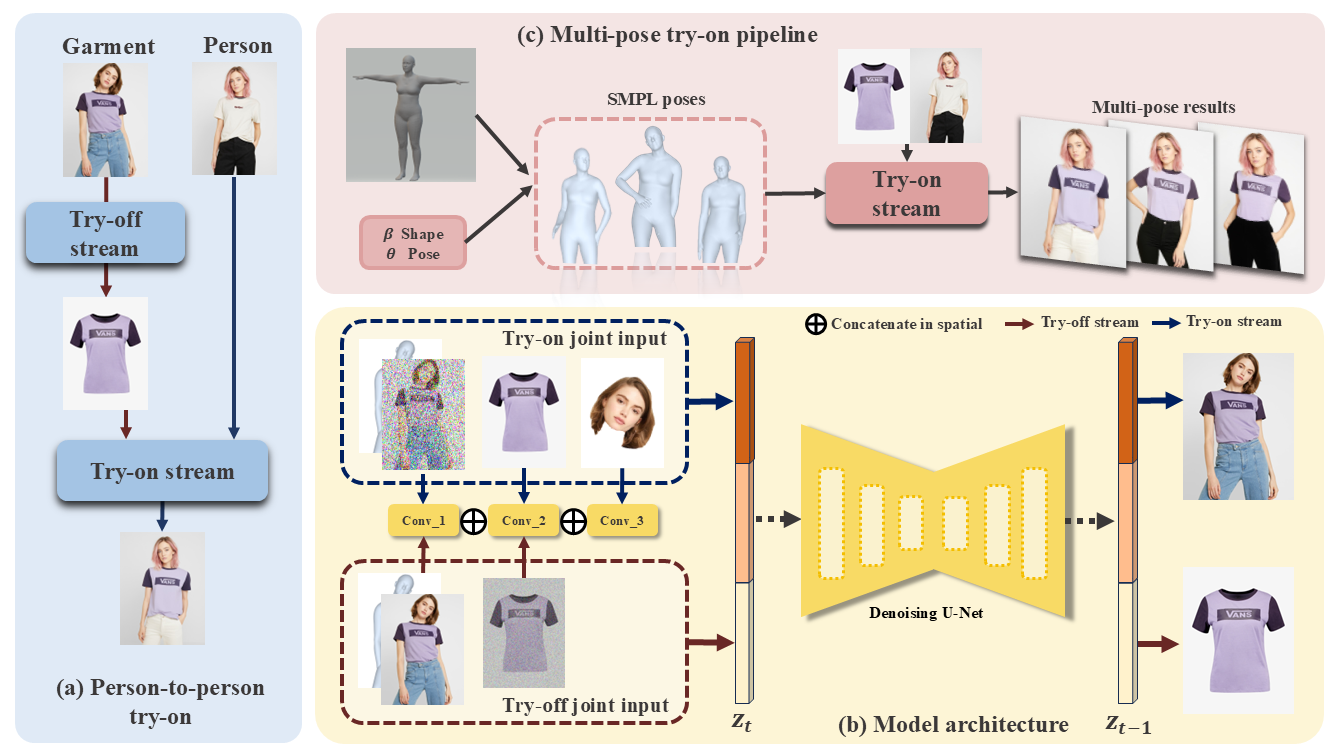
Flexibility: OFMA supports person-to-person try-on and cross-identity garment swapping.
Versatility: OMFA handles multi-pose try-on while maintaining identity consistency.
Recent diffusion-based approaches have made significant advances in image-based virtual try-on, enabling more realistic and end-to-end garment synthesis. However, most existing methods remain constrained by their reliance on exhibition garments and segmentation masks, as well as their limited ability to handle flexible pose variations. These limitations reduce their practicality in real-world scenarios—for instance, users cannot easily transfer garments worn by one person onto another, and the generated try-on results are typically restricted to the same pose as the reference image. In this paper, we introduce OMFA (One Model For All), a unified diffusion framework for both virtual try-on and try-off that operates without the need for exhibition garments and supports arbitrary poses. OMFA is inspired by language modeling, where generation is guided by conditioning prompts (e.g., prompting with a garment to obtain the try-on result). However, our framework differs fundamentally from large language models (LLMs) in two key aspects. First, it employs a bidirectional modeling paradigm that symmetrically allows prompting either from the garment to generate try-on results or from the dressed person to recover the try-off garment. Second, it strictly adheres to Tweedie's formula, enabling faithful estimation of the underlying data distribution during the denoising process. Instead of imposing lower body constraints, OMFA is an entirely mask-free framework that requires only a single portrait and a target garment as input, and is designed to support flexible outfit combinations and cross-person garment transfer, making it better aligned with practical usage scenarios. Additionally, by leveraging SMPL-X-based pose conditioning, OMFA supports multi-view and arbitrary-pose try-on from just one image. Extensive experiments demonstrate that OMFA achieves state-of-the-art results on both try-on and try-off tasks, providing a practical and generalizable solution for virtual garment synthesis.
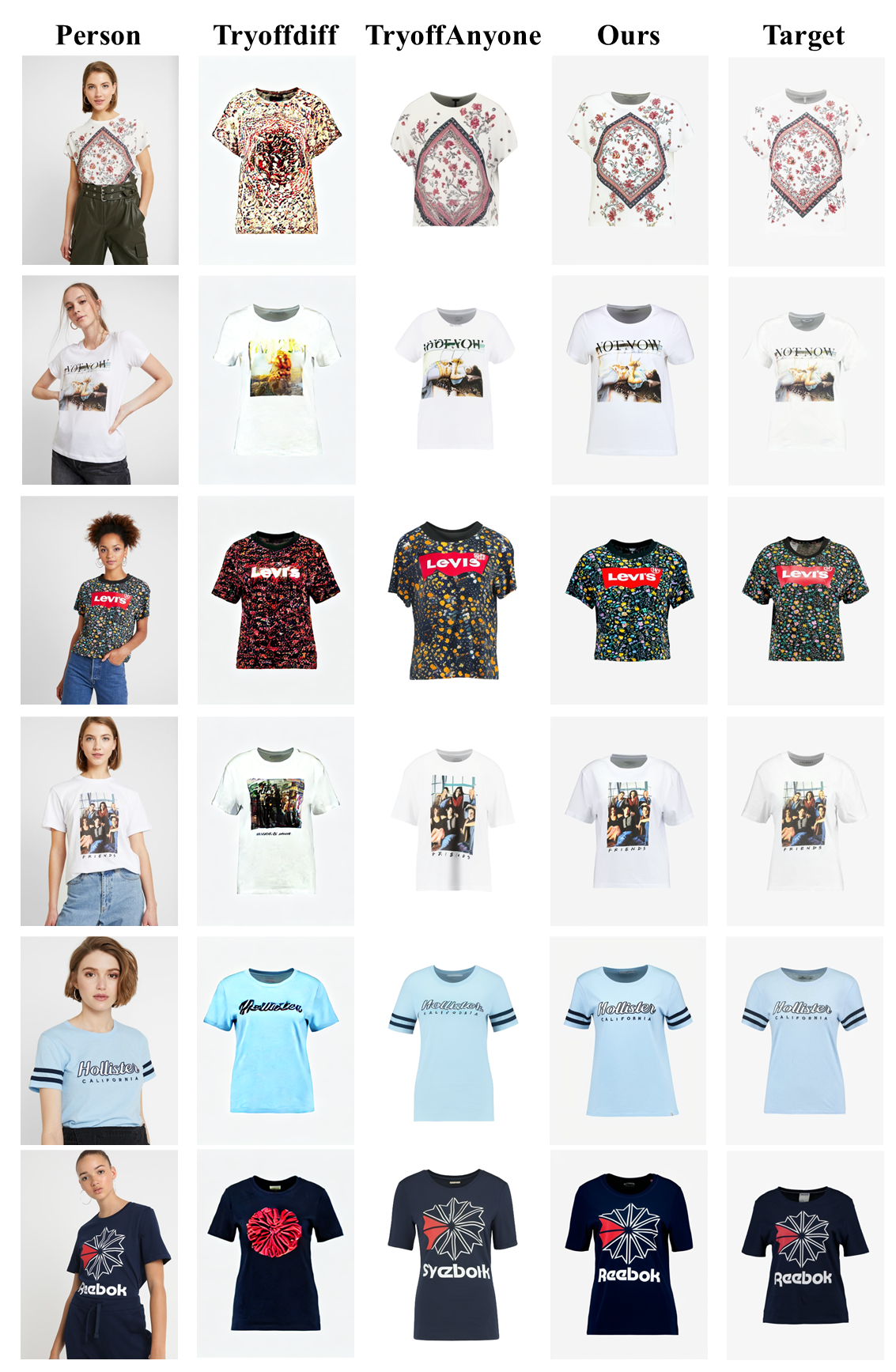
Qualitative comparisons with state-of-the-art methods of Virtual Try-off.

Qualitative result virtual try-off on the DressCode dataset.

Qualitative result virtual try-off on the Deepfashion-MultiModal dataset.

Qualitative comparisons with state-of-the-art methods of Virtual Try-on.